Anthropic Details How It Contains Claude Across Web, Code, and Cowork
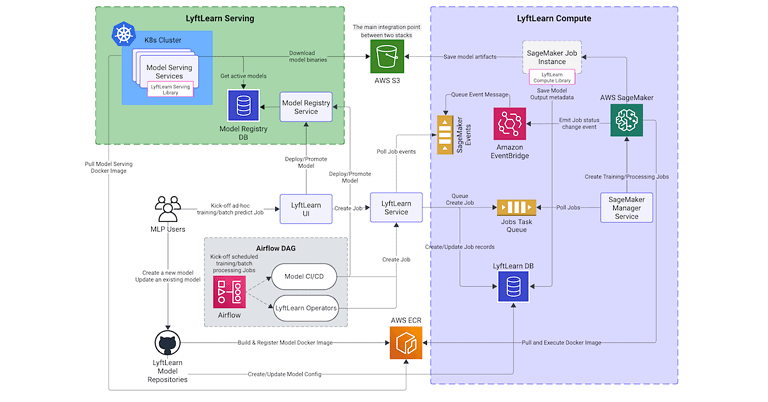
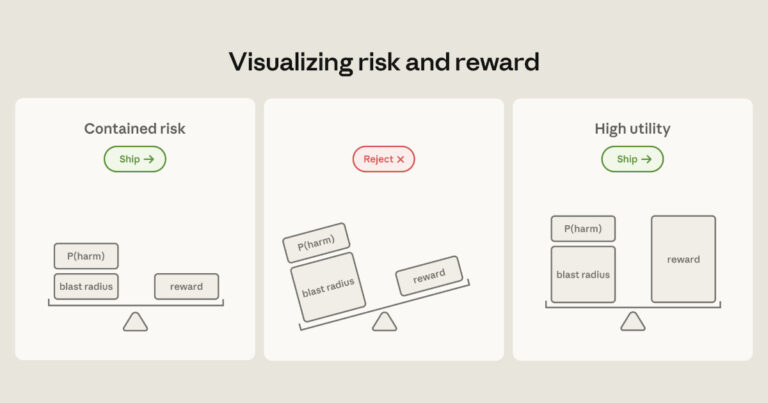
Anthropic recently detailed the containment architectures it uses for Claude across its web, developer, and desktop products. It argues that agent safety depends on placing deterministic limits on an agent’s filesystem, network, and execution environment rather than depending solely on permission prompts or model-level safeguards. Most notably, it examines failures at trust boundaries and along…